
By Shaina Trevino, Research Associate, HEDCO Institute for Evidence-Based Educational Practice, University of Oregon
In 2024, our team at the HEDCO Institute began transforming our systematic reviews into “living” evidence syntheses. Living syntheses are an approach where researchers regularly update a systematic review with the latest research findings. As we began, we faced a familiar challenge: how can we screen thousands of new citations by hand on a regular basis? We had already begun systematic reviews on three topics: school-based depression prevention, school-based anxiety prevention, and the four-day school week. Even with a skilled team, double-screening titles and abstracts can take weeks or months, delaying both review updates and the launch of new projects.Rather than extend our timelines – which would also mean delays in sharing the evidence decision-makers need – we explored workflow efficiencies and decided to pilot DistillerSR’s AI-screening. We wanted to see if the built-in AI could accurately classify the “obvious” cases during title and abstract screening, allowing our reviewers to focus only on the more ambiguous studies.
What is AI-assisted screening?
DistillerSR’s AI-assisted screening algorithm is not a generative AI like ChatGPT. Instead, it’s a supervised learning system trained on our evidence synthesis data, and it learns from previous screening decisions, determining whether a reference was a “Keep” or “Drop” at the title and abstract screening stage. Then for each new reference, it will assign a confidence score between 0 (very likely an exclude) and 1 (very likely an include). Essentially, the AI is telling you, “I’m 95% sure you’d keep this one” or “I’m 70% sure you’d drop that.”
Finding Optimal Thresholds
To apply AI-assisted screening responsibly, we first needed to determine confidence score thresholds, or cutoff values, that would indicate when we felt confident enough to apply the AI-assisted screening with minimal errors.These thresholds determine when a reference can be automatically kept or dropped, when one human screener is required, or when double human screening is needed. To identify reliable thresholds, we compared the AI confidence scores to our previous “Keep” and “Drop” decisions across all three projects. We first generated descriptive summaries of confidence scores for each screening decision (keep or drop), then plotted the number of correct versus incorrect AI decisions at incremental threshold values across all three projects.
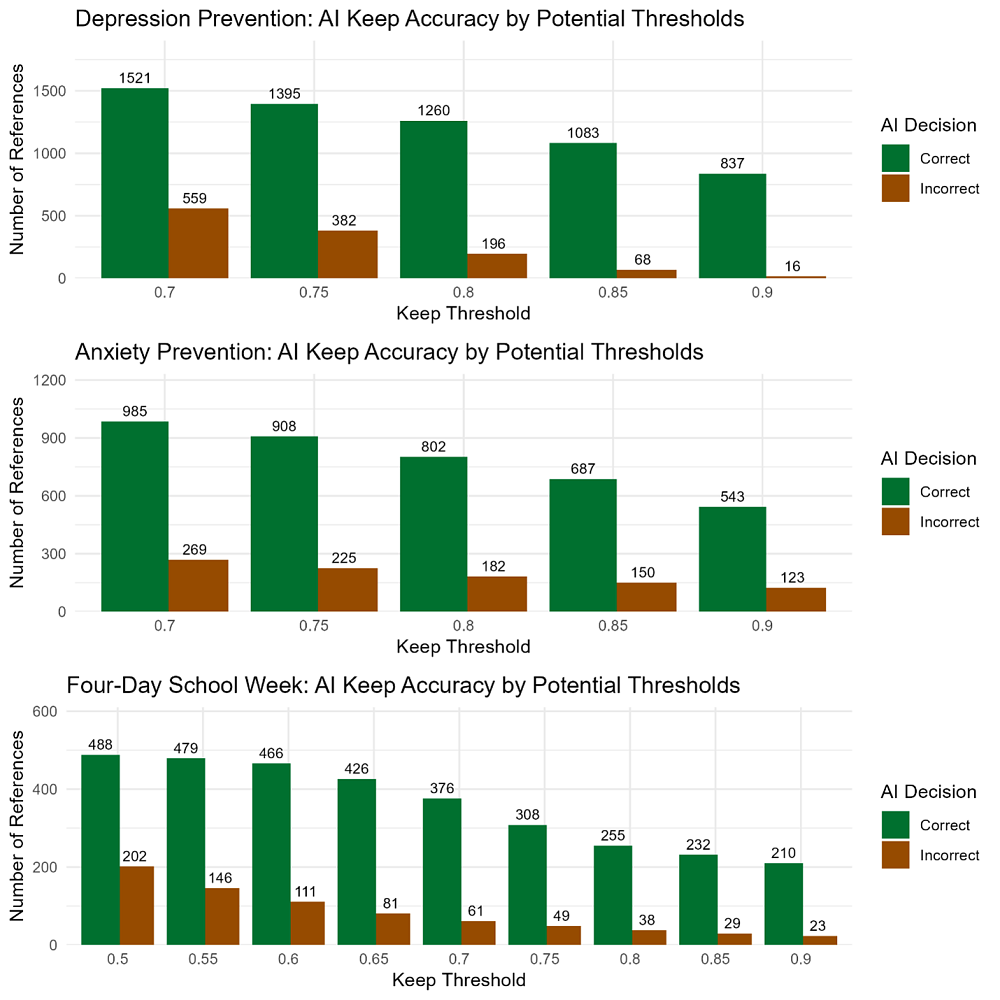
The first plot examined how well the AI correctly classified studies that should be kept at different threshold values. The brown bars show how many studies the AI would correctly keep, and the green bars represent studies that the AI would incorrectly keep (studies that do not meet our eligibility criteria but are kept by the AI). For example, in the Depression Prevention project, if we chose a threshold of 0.85 and automatically kept all references above that cutoff, we would expect to correctly classify over 1,000 references as keeps (7.51% of all references) and have only 68 references incorrectly kept and passed to the next stage.
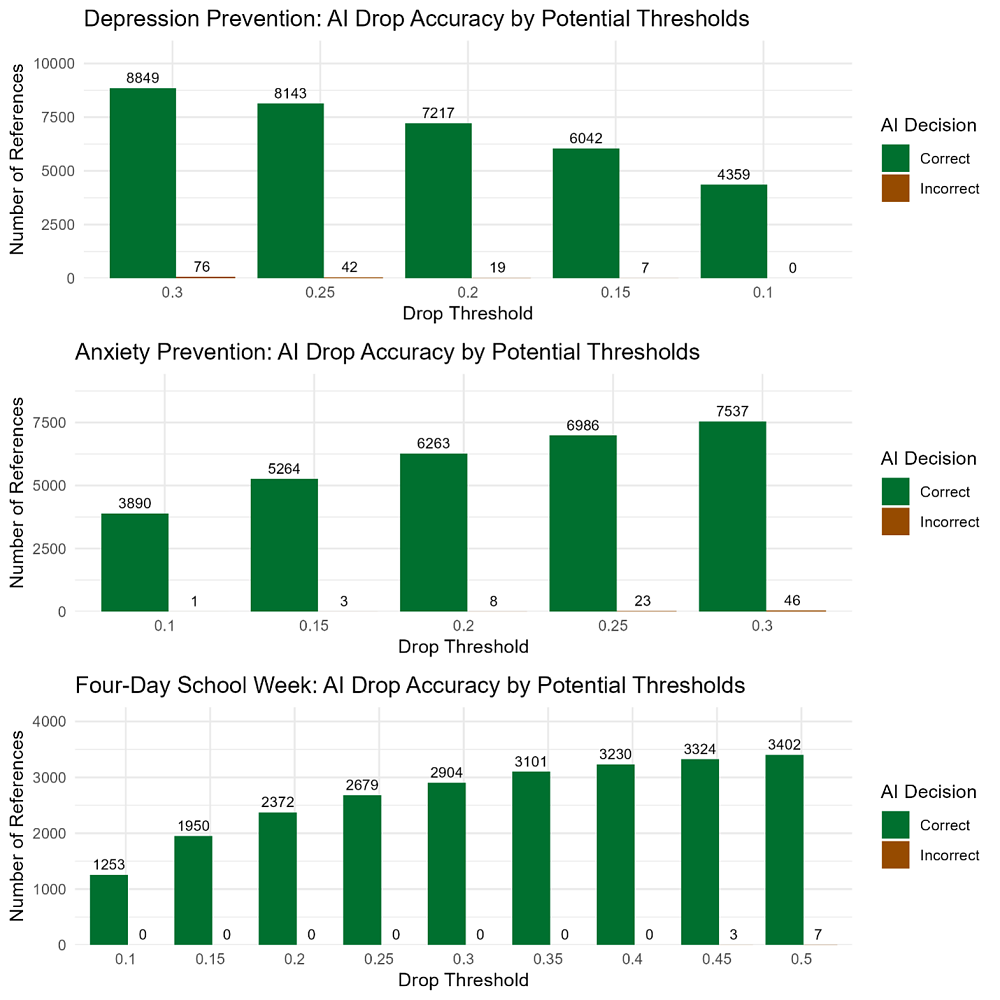
In the second plot, we can see how well the AI correctly classified studies that should be dropped at different threshold values. The brown bars show how many studies the AI would correctly drop, and the green bars represent studies that the AI would incorrectly drop (studies that do meet our eligibility criteria but are excluded by the AI). For example, in the Depression Prevention project, if we chose a threshold of 0.15 and automatically dropped all references below that cutoff, we would expect to correctly classify over 5,000 references as drops (41.89% of all references), but we would have 7 references that were incorrectly dropped.[LC1] [ED2] However, notice that across all 3 projects, if we applied the threshold of 0.10, we could correctly classify about 30% of all references automatically with almost no potential studies being excluded.
Examining both plots and descriptive statistics across all projects we were able to determine:
Examining both plots and descriptive statistics across all projects we were able to determine:
- All references with an AI score less than .1, we dropped during our initial round of human screening
- All references that we ultimately deemed eligible for our study had an AI score greater than .3
- Nearly all references with an AI score greater than .9, we kept during screening
Based on this, we developed a set of thresholds for applying AI-assisted screening among our projects
- References with scores less than .1 could be automatically dropped
- References with scores less than .3 should be double-screened with one human reviewer and one AI screening decision
- References with scores greater than .9 could be automatically kept
- Remaining references (scores .3-.9) need to be manually double-screened by human reviewers
Accelerating our Workflow
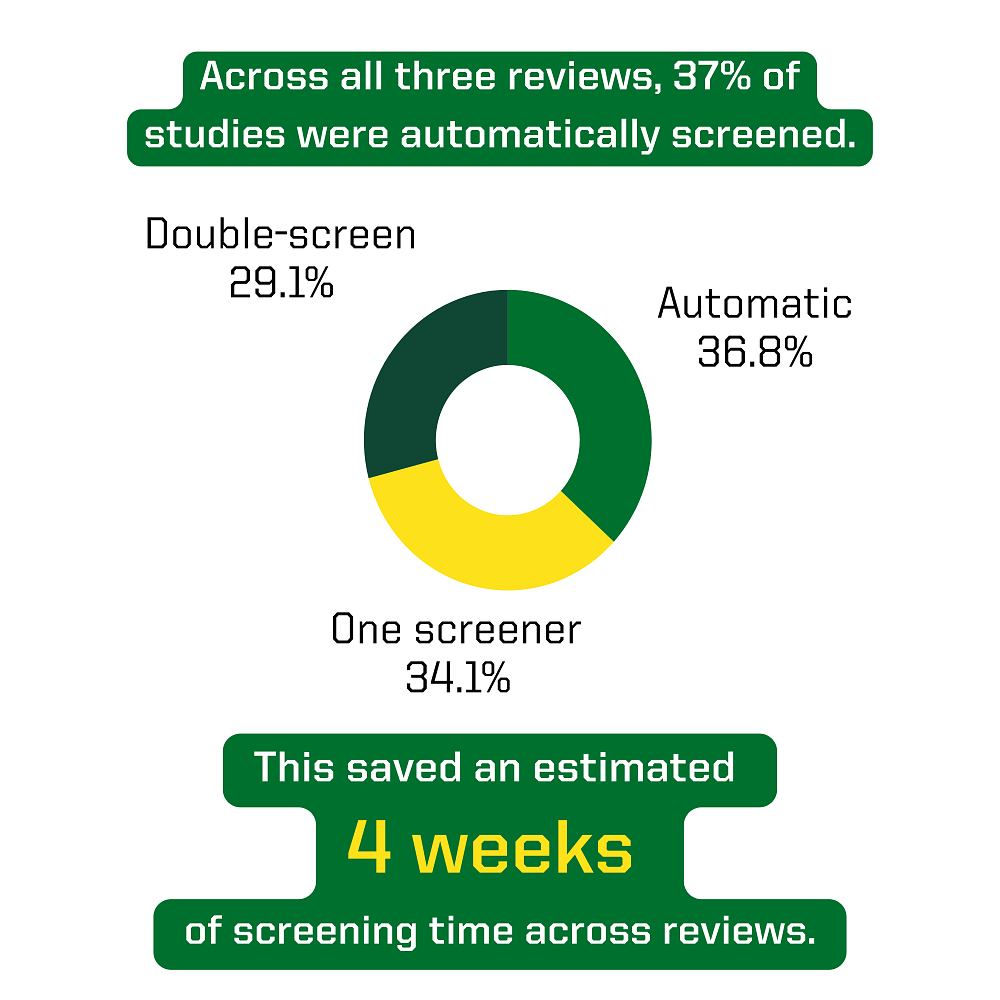
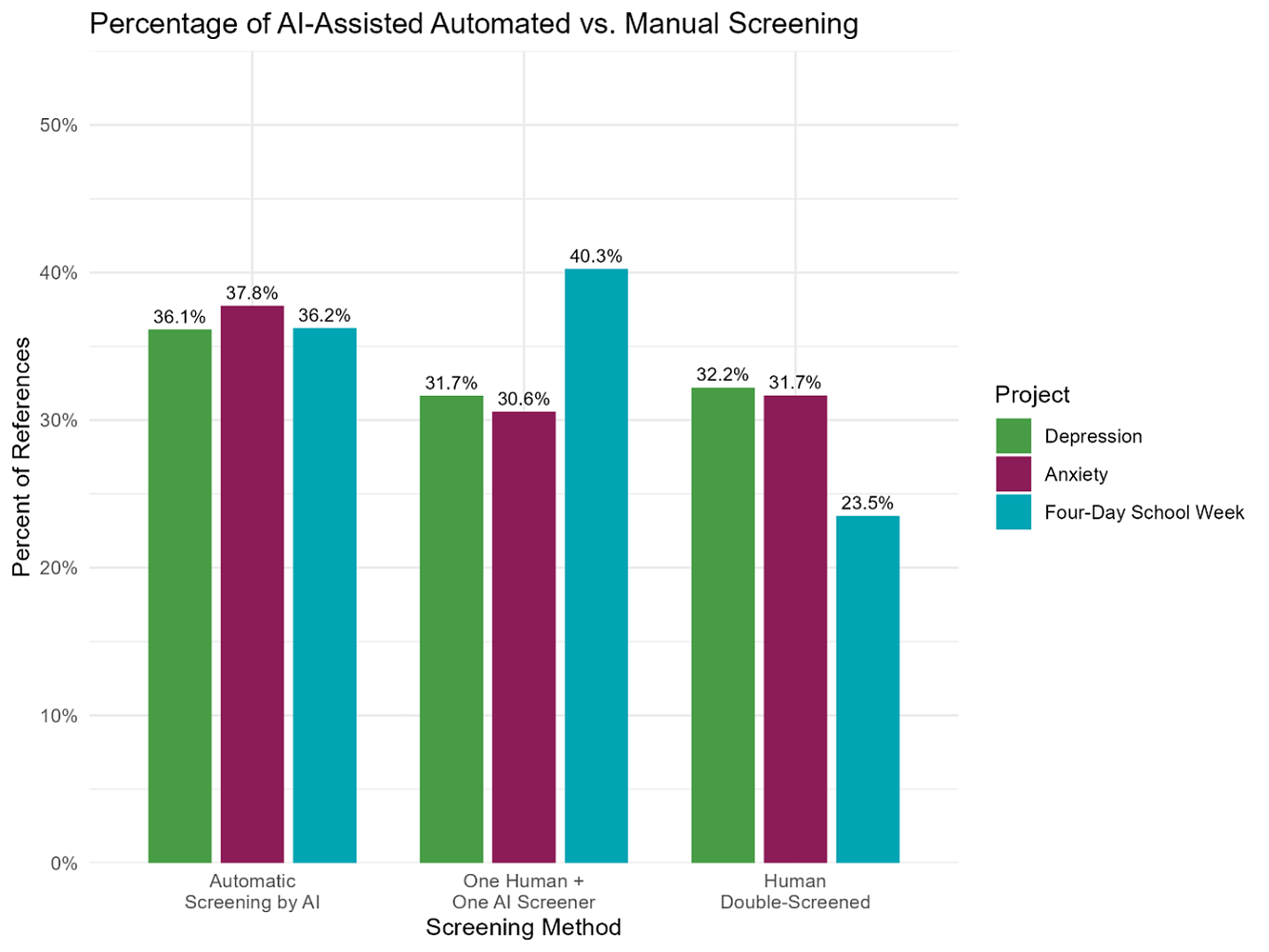
By applying AI-assisted screening using our thresholds, we were able to cut our manual screening effort by about half. Across all three living systematic reviews, AI-assisted screening allowed us to:
- Automatically process over a third of new references
- Require only one screener for about a third of new references
- Only double-screen almost a third of new references
In our first update cycle, we were able to save an estimated 4 weeks of screening time across all three reviews. Screeners can now focus their attention on the more ambiguous abstracts where their domain expertise is most needed. Beyond time saved, utilizing AI brings consistency to the screening process. References with very high confidence scores are all treated the same way, eliminating human drift that inevitably occurs during quick, repetitive tasks.
Through using defined thresholds, our false-drop rate was virtually zero – meaning we didn’t automatically drop any reference that was potentially an included study. Additionally, our false-keep errors stayed under .5%, so we didn’t add too much additional effort for reviewers during the PDF retrieval and full-text eligibility stages.
Looking Ahead
Excited by the efficiency gains from using DistillerSR’s built-in AI-screening feature, we’re now exploring other ways we can use AI to optimize our living review workflows. We are now testing DistillerSR advanced AI tools to train a bespoke AI classifier using data from all three reviews (anxiety, depression, and four-day school week). Once trained and validated, we will be able to start new reviews and automatically classify and screen references at the start, rather than requiring a large amount of manual screening in each project before AI-assisted screening can be leveraged.
Could AI Screening Work for You?
Utilizing AI to accelerate title and abstract screening in large-scale or ongoing reviews can be a game-changer. It can accelerate your workflow, reduce manual effort and errors, and still preserve the rigor of evidence syntheses. If you are curious about integrating AI:
- Start small: Run your previous screening data through different AI tools to examine the correct and incorrect classifications.
- Audit closely: Compare AI decisions to decisions made by your human screeners to assess error rates.
- Specify thresholds: Decide on what error rate is acceptable and determine what thresholds return results with your error rate.
- Monitor and iterate: As your project grows, repeat audits, revisit thresholds, and retrain on new data to improve efficiency and accuracy.
Summary
At first glance, trusting AI with thousands of citations can feel risky. Yet, our experience with AI-assisted title and abstract screening showed that by auditing the AI scores against our own historic decisions, we could determine thresholds that produced little to no misclassified references. Using these thresholds, we saved about half of our manual screening effort. These efficiency gains will scale with time as more updates are needed. The result? Faster updates, preserved rigor, and more time for translating evidence to action.
